最近使用的Java8,就Lamba和Stream的使用整理了笔记,所以仅供参考和学习。
JDK8 Lambda & Stream使用笔记
简介
Lambda
一段带有输入参数的可执行语句块。
Java8的lambda表达式给我们提供了创建SAM(Single Abstract Method)接口更加简单的语法糖
Stream
Stream是元素的集合,这点让Stream看起来有些类似Iterator
可以支持顺序和并行的对原Stream进行汇聚的操作
高级版本的Iterator
Lambda语法
抽象语法结构
(Type1 param1, Type2 param2, ..., TypeN paramN) -> {
statment1;
statment2;
//.............
return statmentM;
}
简化Lambda表达式声明
1. 参数类型省略
(param1,param2, ..., paramN) -> {
statment1;
statment2;
//.............
return statmentM;
}
List<String> lowercaseNames = names.stream().map((String name) -> {return name.toLowerCase();}).collect(Collectors.toList());
//编译器都可以从上下文环境中推断出lambda表达式的参数类型
List<String> lowercaseNames = names.stream().map((name) -> {return name.toLowerCase();}).collect(Collectors.toList());
2. 当lambda表达式的参数个数只有一个,可以省略小括号
param1 -> {
statment1;
statment2;
//.............
return statmentM;
}
List<String> lowercaseNames = names.stream().map(name -> {return name.toLowerCase();}).collect(Collectors.toList());
3. 当lambda表达式只包含一条语句时,可以省略大括号、return和语句结尾的分号
param1 -> statment
List<String> lowercaseNames = names.stream().map(name -> name.toLowerCase()).collect(Collectors.toList());
4. 使用Method Reference ``` //注意,这段代码在Idea 13.0.2中显示有错误,但是可以正常运行 List<String> lowercaseNames = names.stream().map(String::toLowerCase).collect(Collectors.toList()); ```
Lambda表达式眼中的外部世界
1. lambda表达式的三个重要组成部分:
- 输入参数
- 可执行语句
- 存放外部变量的空间
2. 外部变量被lambda表达式引用,编译器会隐式的把其当成final来处理
<font color=#929>以前java的匿名内部类在访问外部变量的时候,外部变量必须用final修饰。Bingo,在java8对这个限制做了优化(前面说的小小优化),可以不用显示使用final修饰,但是编译器隐式当成final来处理</font>
String[] array = {"a", "b", "c"};
for(Integer i : Lists.newArrayList(1,2,3)){
Stream.of(array).map(item -> Strings.padEnd(item, i, '@')).forEach(System.out::println);
}
String[] array = {"a", "b", "c"};
for(int i = 1; i<4; i++){
Stream.of(array).map(item -> Strings.padEnd(item, i, '@')).forEach(System.out::println);
}
Lambda表达式眼中的this
不是指向lambda表达式产生的那个SAM对象,而是声明它的外部对象。[外部类作用域]
简化Lambda表达式中方法和构造器引用
1. 方法引用
//等同于把lambda表达式的参数直接当成instanceMethod|staticMethod的参数来调用
objectName::instanceMethod
ClassName::staticMethod
//等同于把lambda表达式的第一个参数当成instanceMethod的目标对象,其他剩余参数当成该方法的参数
ClassName::instanceMethod
System.out::println等同于x->System.out.println(x)
Math::max等同于(x, y)->Math.max(x,y)
String::toLowerCase等同于x->x.toLowerCase()
2. 构造器引用
ClassName::new,把lambda表达式的参数当成ClassName构造器的参数 。例如BigDecimal::new等同于x->new BigDecimal(x)。
Stream语法
通用语法
- 创建Stream
- 转换Stream: 每次转换原有Stream对象不改变,返回一个新的Stream对象(**可以有多次转换**)
- 汇聚(Reduce)Stream

创建Stream
- 通过Stream接口的静态工厂方法(注意:Java8里接口可以带静态方法)
- 通过Collection接口的默认方法(默认方法:Default method,也是Java8中的一个新特性,就是接口中的一个带有实现的方法,后续文章会有介绍)–stream(),把一个Collection对象转换成Stream
使用Stream静态方法来创建Stream
- of方法:有两个overload方法,一个接受变长参数,一个接口单一值
Stream<Integer> integerStream = Stream.of(1, 2, 3, 5);
Stream<String> stringStream = Stream.of("taobao");
- generator方法:生成一个无限长度的Stream,其元素的生成是通过给定的Supplier(这个接口可以看成一个对象的工厂,每次调用返回一个给定类型的对象)
Stream.generate(new Supplier<Double>() {
@Override
public Double get() {
return Math.random();
}
});
Stream.generate(() -> Math.random());
Stream.generate(Math::random);
三条语句的作用都是一样的,只是使用了lambda表达式和方法引用的语法来简化代码。每条语句其实都是生成一个无限长度的Stream,其中值是随机的。这个无限长度Stream是懒加载,一般这种无限长度的Stream都会配合Stream的limit()方法来用。
- iterate方法:也是生成无限长度的Stream,和generator不同的是,其元素的生成是重复对给定的种子值(seed)调用用户指定函数来生成的。其中包含的元素可以认为是:seed,f(seed),f(f(seed))无限循环
//先获取一个无限长度的正整数集合的Stream,然后取出前10个打印。千万记住使用limit方法,不然会无限打印下去
Stream.iterate(1, item -> item + 1).limit(10).forEach(System.out::println);
通过Collection子类获取Stream
查看Java doc就可以发现Collection接口有一个stream方法,所以其所有子类都都可以获取对应的Stream对象。
public interface Collection<E> extends Iterable<E> {
//其他方法省略
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
}
转换Stream
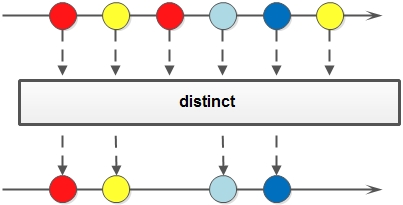
distinct
对于Stream中包含的元素进行去重操作(去重逻辑依赖元素的equals方法),新生成的Stream中没有重复的元素
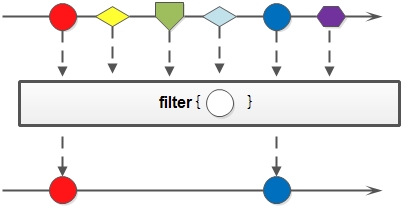
filter
对于Stream中包含的元素使用给定的过滤函数进行过滤操作,新生成的Stream只包含符合条件的元素
map
对于Stream中包含的元素使用给定的转换函数进行转换操作,新生成的Stream只包含转换生成的元素。这个方法有三个对于原始类型的变种方法,分别是:mapToInt,mapToLong和mapToDouble。这三个方法也比较好理解,比如mapToInt就是把原始Stream转换成一个新的Stream,这个新生成的Stream中的元素都是int类型。之所以会有这样三个变种方法,可以免除自动装箱/拆箱的额外消耗
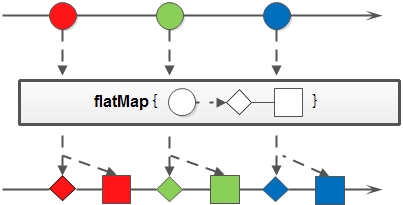
flatMap
和map类似,不同的是其每个元素转换得到的是Stream对象,会把子Stream中的元素压缩到父集合中
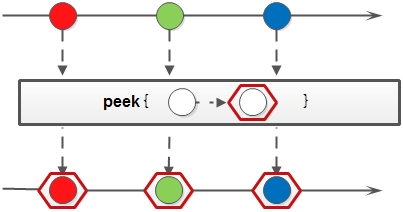
peek
生成一个包含原Stream的所有元素的新Stream,同时会提供一个消费函数(Consumer实例),新Stream每个元素被消费的时候都会执行给定的消费函数
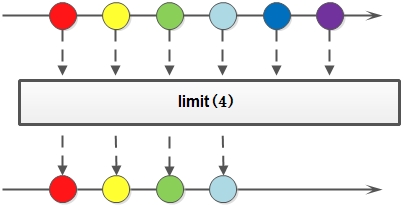
limit
对一个Stream进行截断操作,获取其前N个元素,如果原Stream中包含的元素个数小于N,那就获取其所有的元素
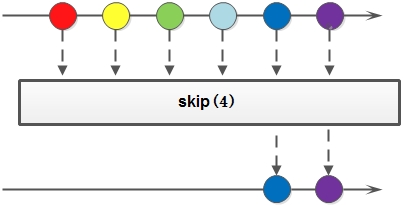
skip
返回一个丢弃原Stream的前N个元素后剩下元素组成的新Stream,如果原Stream中包含的元素个数小于N,那么返回空Stream
[声明式编程]上述方法复合使用
这段代码演示了上面介绍的所有转换方法(除了flatMap),简单解释一下这段代码的含义:给定一个Integer类型的List,获取其对应的Stream对象,然后进行过滤掉null,再去重,再每 个元素乘以2,再每个元素被消费的时候打印自身,在跳过前两个元素,最后去前四个元素进行加和运算。
List<Integer> nums = Lists.newArrayList(1,1,null,2,3,4,null,5,6,7,8,9,10);
System.out.println("sum is:"+nums.stream().filter(num -> num != null)
//1,1,2,3,4,5,6,7,8,9,10
//.peek(x -> System.out.println("peek0: "+x))
.distinct()
//1,2,3,4,5,6,7,8,9,10
.mapToInt(num -> num * 2)
//2,4,6,8,10,12
.skip(2)
//6,8,10,12,14,16,18,20
.limit(4)
.peek(System.out::println)
//6,8,10,12
.sum());
//36
//result
6
8
10
12
sum is:36
<font color=#929>peek函数是针对最终stream进行消费自身操作的。</font>
转换操作都是lazy的,多个转换操作只会在汇聚操作(见下节)的时候融合起来,一次循环完成。我们可以这样简单的理解,Stream里有个操作函数的集合,每次转换操作就是把转换函数放入这个集合中,在汇聚操作的时候循环Stream对应的集合,然后对每个元素执行所有的函数
汇聚Stream
汇聚操作(也称为折叠)接受一个元素序列为输入,反复使用某个合并操作,把序列中的元素合并成一个汇总的结果。比如查找一个数字列表的总和或者最大值,或者把这些数字累积成一个List对象。Stream接口有一些通用的汇聚操作,比如reduce()和collect();也有一些特定用途的汇聚操作,比如sum(),max()和count()。
<font color=#379>注意:sum方法不是所有的Stream对象都有的,只有IntStream、LongStream和DoubleStream是实例才有</font>
可变汇聚
把输入的元素们累积到一个可变的容器中,比如Collection或者StringBuilder
<R> R collect(Supplier<R> supplier,
BiConsumer<R, ? super T> accumulator,
BiConsumer<R, R> combiner);
参数说明
- Supplier supplier是一个工厂函数,用来生成一个新的容器
- BiConsumer accumulator也是一个函数,用来把Stream中的元素添加到结果容器中
- BiConsumer combiner还是一个函数,用来把中间状态的多个结果容器合并成为一个(并发的时候会用到)
/** 对一个元素是Integer类型的List,先过滤掉全部的null,然后把剩下的元素收集到一个新的List中*/
List<Integer> nums = Lists.newArrayList(1,1,null,2,3,4,null,5,6,7,8,9,10);
List<Integer> numsWithoutNull = nums.stream().filter(num -> num != null).
collect(() -> new ArrayList<Integer>(),
(list, item) -> list.add(item),
(list1, list2) -> list1.addAll(list2));
步骤分析
- 第一个函数生成一个新的ArrayList实例
- 第二个函数接受两个参数,第一个是前面生成的ArrayList对象,二个是stream中包含的元素,函数体就是把stream中的元素加入ArrayList对象中。第二个函数被反复调用直到原stream的元素被消费完毕
- 第三个函数也是接受两个参数,这两个都是ArrayList类型的,函数体就是把第二个ArrayList全部加入到第一个中
<R, A> R collect(Collector<? super T, A, R> collector);
Collectors.toCollection()收集到Collection中
Collectors.toList()收集到List中
Collectors.toSet()收集到Set中
/**Ex1代码简化*/
List<Integer> numsWithoutNull = nums.stream().filter(num -> num != null).collect(Collectors.toList());
其他汇聚
除去可变汇聚剩下的,一般都不是通过反复修改某个可变对象,而是通过把前一次的汇聚结果当成下一次的入参,反复如此。比如reduce,count,allMatch
-
reduce方法
reduce方法非常的通用,后面介绍的count,sum等都可以使用其实现。reduce方法有三个override的方法
/**方法定义*/
Optional<T> reduce(BinaryOperator<T> accumulator);
/**示例*/
List<Integer> ints = Lists.newArrayList(1,2,3,4,5,6,7,8,9,10);
System.out.println("ints sum is:" + ints.stream().reduce((sum, item) -> sum + item).get());
接受一个BinaryOperator类型的参数,在使用的时候我们可以用lambda表达式来。
代码分析
reduce方法接受一个函数,这个函数有两个参数,第一个参数是上次函数执行的返回值(也称为中间结果),第二个参数是stream中的元素,这个函数把这两个值相加,得到的和会被赋值给下次执行这个函数的第一个参数。要注意的是:第一次执行的时候第一个参数的值是Stream的第一个元素,第二个参数是Stream的第二个元素。这个方法返回值类型是Optional,这是Java8防止出现NPE的一种可行方法,可以简单简单的认为是一个容器,其中可能会包含0个或者1个对象。 这个过程可视化的结果如图:
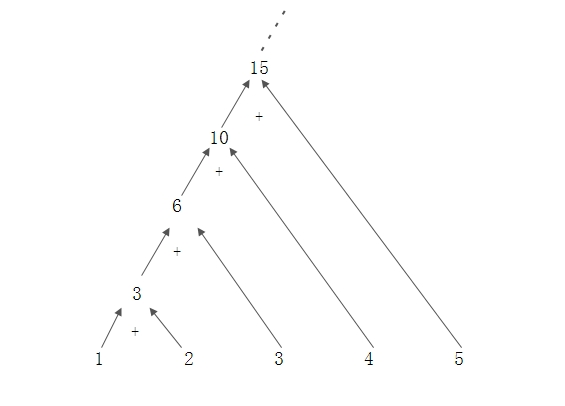
/**方法定义*/
T reduce(T identity, BinaryOperator<T> accumulator);
/**示例*/
List<Integer> ints = Lists.newArrayList(1,2,3,4,5,6,7,8,9,10);
System.out.println("ints sum is:" + ints.stream().reduce(0, (sum, item) -> sum + item));
这个定义与上面已经介绍过的基本一致,不同的是:它允许用户提供一个循环计算的初始值,如果Stream为空,就直接返回该值。而且这个方法不会返回Optional
-
count方法
获取Stream中元素的个数
List<Integer> ints = Lists.newArrayList(1,2,3,4,5,6,7,8,9,10);
System.out.println("ints sum is:" + ints.stream().count());
- allMatch:是不是Stream中的所有元素都满足给定的匹配条件
- anyMatch:Stream中是否存在任何一个元素满足匹配条件
- findFirst: 返回Stream中的第一个元素,如果Stream为空,返回空Optional
- noneMatch:是不是Stream中的所有元素都不满足给定的匹配条件
-
max和min:使用给定的比较器(Operator),返回Stream中的最大 最小值
/** allMatch和max示例*/
List<Integer> ints = Lists.newArrayList(1,2,3,4,5,6,7,8,9,10);
System.out.println(ints.stream().allMatch(item -> item < 100));
ints.stream().max((o1, o2) > o1.compareTo(o2)).ifPresent(System.out::println);
REFERENCES
更多
扫码关注“架构探险之道”,回复
文章名称获取更多源码和文章资源

知识星球(扫码加入获取源码和文章资源链接)